

On this page
什么是MHA
MHA(Master High Availability)是用于提高数据库集群可用性的方案,基于虚拟IP技术,可以实现在Master故障时,在30s内实现故障转移并确保数据一致性。可以理解为MHA就是作用于数据库集群的KeepAlived。
MHA工作原理
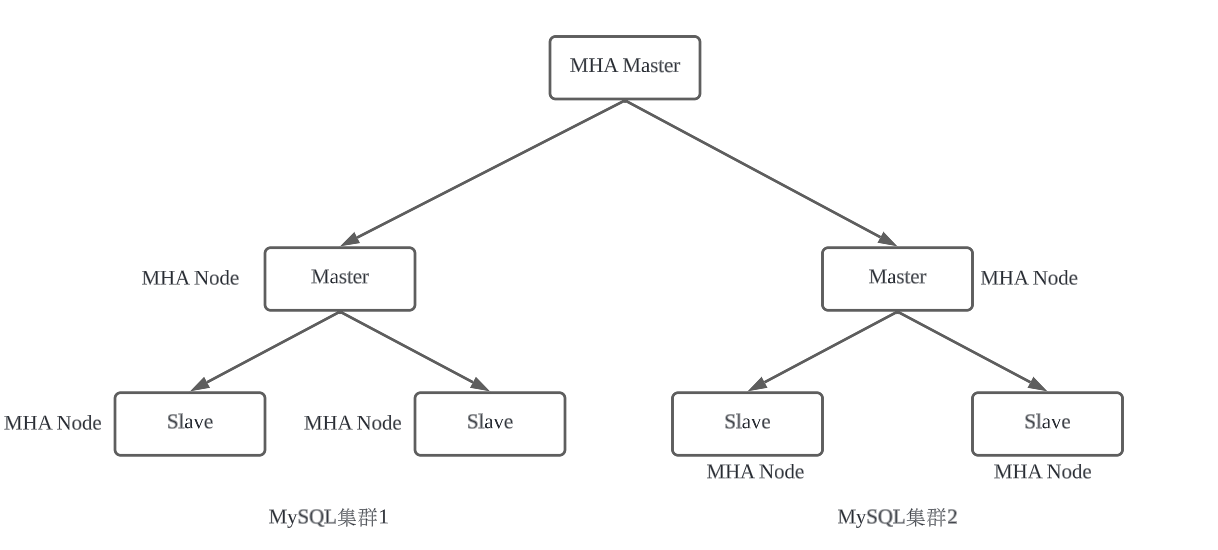
MHA的组成
MHA由MHA Manager和MHA Node组成,其中Manager相当于服务端,Node相当于客户端;
Manager可以部署在Master或Slave机器上,也可以单独的部署在一台机器上;一般建议部署在一台单独的机器上,因为Manager是用于探测数据库实例是否在线和进行故障转移的核心程序,如果部署在Master上,一旦Master机器报销,整个数据库集群的不再可以;另外,如果部署在Slave机器上,那么这台机器就不能够被提升为Master。
Node需要部署在所有MySQL数据库实例的机器上。
MHA故障转移流程
- Manager会每隔一段时间(可以由用户在配置文件中指定)对主库进行一次探测;
- 如果Manager检测到Master故障,会执行:
- 尝试从其他Node发起ssh链接;
- 尝试从其他Node发起mysql链接。
- 如果两种链接皆失败,则开始进行故障转移:
- 通过对比relay log,找到拥有最新数据的从库;
- 将最新的从库中的新数据同步到其他从库中;
- 提升从库为新的主库(如果没有预先指定,则提升拥有最新数据的从库为新主库);
- 通过原主库的binlog补全新主库的数据;
- 其他从库CHANGE MASTER TO新的主库,并进行数据同步。
部署MHA
环境准备
使用三台机器,其中MySQL一主一从,Manager单独布置在一台管理机器上。
| 身份 | 主机名 | 公网ip | 内网ip | 开启binlog | 开启GTID |
|---|---|---|---|---|---|
| Master | db-51 | 10.0.0.51 | 172.16.1.51 | yes | yes |
| Slave | db-52 | 10.0.0.52 | 172.16.1.52 | yes | yes |
| Manager | master-61 | 10.0.0.61 | 172.16.1.61 | - | - |
配置文件
[mysqld]
port=3306
user=mysql
basedir=/opt/mysql
datadir=/mysql_data/mysql_3306
socket=/tmp/mysql.sock
server_id=51
log_bin=/mysql_data/binlog/mysql-bin
autocommit=0
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
socket=/tmp/mysql.sock
除了server_id其他都一样
配置主从复制
创建复制账号
--在master机器上执行--
grant replication slave on*.* to repl@'172.16.1.%' identified by '123456';
从库进行连接
change master to master_host='172.16.1.51', master_user='repl', master_password='123456' , MASTER_AUTO_POSITION=1;
start slave;
使三个节点之间互相免密登录:
ssh-keygen
ssh-copy-id [email protected]
ssh-keygen
ssh-copy-id [email protected]
ssh-keygen
ssh-copy-id [email protected]
安装MHA
为所有节点安装环境依赖
yum install -y perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker perl-CPAN perl-Time-HiRes
三个节点都安装MHA Node
# 获得软件源
wget https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58-0.el7.centos.noarch.rpm
# 安装
yum localinstall -y mha4mysql-node-0.58-0.el7.centos.noarch.rpm
安装MHA Manager
MHA Manager Github仓库
这里由于只用了两台机器,因此Manager必须装在另外单独的一台主机上,否则对于一主一从配置来说,装在主库上,挂掉后会导致MHA失效;装在从库上,会导致无法提升为主库;
# 获取软件源
wget https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
# 安装
yum localinstall -y mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
配置MHA
为所有节点创建MHA用户
因为目前已经配置好了主从复制,所以在主库上创建就可以了,会自动同步到从库。
grant all privileges on *.* to mha@'%' identified by '123456';
创建MHA Manager配置文件
创建目录
mkdir -p /etc/mha
mkdir -p /var/log/mha/app1
配置文件
[server default]
manager_log=/var/log/mha/app1/manager.log
manager_workdir=/var/log/mha/app1.log
master_binlog_dir=/mysql_binlog/
# 这里涉及到vip偏移脚本,在后面
# master_ip_failover_script=/usr/local/bin/master_ip_failover
user=mha
password=123456
ping_interval=5
repl_user=repl
repl_password=123456
ssh_user=root
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
检查环境配置
# 检查ssh免密登录
masterha_check_ssh --conf=/etc/mha/app1.cnf
# 检查主从复制
masterha_check_repl --conf=/etc/mha/app1.cnf
开发Virtual IP漂移脚本
脚本路径:/usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '172.16.1.55/24';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig eth1:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth1:$key down";
my $ssh_Bcast_arp="/sbin/arping -I eth1 -c 3 -A 10.0.0.55";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
增加可执行权限:
chmod +x /usr/local/bin/master_ip_failover
将脚本路径加入到配置文件中:
master_ip_failover_script=/usr/local/bin/master_ip_failover
配置虚拟IP
在db-51机器上创建虚拟IP
# 这里的虚拟IP必须是和perl脚本上的一致,并且虚拟ip必须是网段内未被占用的IP
ifconfig eth1:1 172.16.1.55/24
重启MHA
# 停止MHA
masterha_stop --conf=/etc/mha/app1.cnf
# 启动MHA(后台运行)
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover /var/log/mha/app1/manager.log 2>&1 &
# 检查MHA运行状态
masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:2220) is running(0:PING_OK), master:172.16.1.51
此时MHA就已经部署完毕了。
模拟故障
实时查看manager日志:
tail -f /var/log/mha/app1/manager.log
停止当前mysql主库
systemctl stop mysqld
此时查看日志,可以发现manager尝试多次连接mysql主库失败,manager进行了主库身份转移。
Tue Aug 22 15:56:07 2023 - [warning] Got error on MySQL select ping: 2006 (MySQL server has gone away)
Tue Aug 22 15:56:07 2023 - [info] Executing SSH check script: exit 0
Tue Aug 22 15:56:07 2023 - [info] HealthCheck: SSH to 172.16.1.51 is reachable.
Tue Aug 22 15:56:12 2023 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '172.16.1.51' (111))
Tue Aug 22 15:56:12 2023 - [warning] Connection failed 2 time(s)..
Tue Aug 22 15:56:17 2023 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '172.16.1.51' (111))
Tue Aug 22 15:56:17 2023 - [warning] Connection failed 3 time(s)..
Tue Aug 22 15:56:22 2023 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '172.16.1.51' (111))
Tue Aug 22 15:56:22 2023 - [warning] Connection failed 4 time(s)..
Tue Aug 22 15:56:22 2023 - [warning] Master is not reachable from health checker!
Tue Aug 22 15:56:22 2023 - [warning] Master 172.16.1.51(172.16.1.51:3306) is not reachable!
Tue Aug 22 15:56:22 2023 - [warning] SSH is reachable.
Tue Aug 22 15:56:22 2023 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/mha/app1.cnf again, and trying to connect to all servers to check server status..
Tue Aug 22 15:56:22 2023 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Aug 22 15:56:22 2023 - [info] Reading application default configuration from /etc/mha/app1.cnf..
Tue Aug 22 15:56:22 2023 - [info] Reading server configuration from /etc/mha/app1.cnf..
Tue Aug 22 15:56:23 2023 - [info] GTID failover mode = 1
Tue Aug 22 15:56:23 2023 - [info] Dead Servers:
Tue Aug 22 15:56:23 2023 - [info] 172.16.1.51(172.16.1.51:3306)
Tue Aug 22 15:56:23 2023 - [info] Alive Servers:
Tue Aug 22 15:56:23 2023 - [info] 172.16.1.52(172.16.1.52:3306)
Tue Aug 22 15:56:23 2023 - [info] Alive Slaves:
Tue Aug 22 15:56:23 2023 - [info] 172.16.1.52(172.16.1.52:3306) Version=5.7.28-log (oldest major version between slaves) log-bin:enabled
Tue Aug 22 15:56:23 2023 - [info] GTID ON
Tue Aug 22 15:56:23 2023 - [info] Replicating from 172.16.1.51(172.16.1.51:3306)
Tue Aug 22 15:56:23 2023 - [info] Checking slave configurations..
Tue Aug 22 15:56:23 2023 - [info] read_only=1 is not set on slave 172.16.1.52(172.16.1.52:3306).
Tue Aug 22 15:56:23 2023 - [info] Checking replication filtering settings..
Tue Aug 22 15:56:23 2023 - [info] Replication filtering check ok.
Tue Aug 22 15:56:23 2023 - [info] Master is down!
Tue Aug 22 15:56:23 2023 - [info] Terminating monitoring script.
Tue Aug 22 15:56:23 2023 - [info] Got exit code 20 (Master dead).
Tue Aug 22 15:56:23 2023 - [info] MHA::MasterFailover version 0.58.
Tue Aug 22 15:56:23 2023 - [info] Starting master failover.
Tue Aug 22 15:56:23 2023 - [info]
Tue Aug 22 15:56:23 2023 - [info] * Phase 1: Configuration Check Phase..
Tue Aug 22 15:56:23 2023 - [info]
Tue Aug 22 15:56:24 2023 - [info] GTID failover mode = 1
Tue Aug 22 15:56:24 2023 - [info] Dead Servers:
Tue Aug 22 15:56:24 2023 - [info] 172.16.1.51(172.16.1.51:3306)
Tue Aug 22 15:56:24 2023 - [info] Checking master reachability via MySQL(double check)...
Tue Aug 22 15:56:24 2023 - [info] ok.
Tue Aug 22 15:56:24 2023 - [info] Alive Servers:
Tue Aug 22 15:56:24 2023 - [info] 172.16.1.52(172.16.1.52:3306)
Tue Aug 22 15:56:24 2023 - [info] Alive Slaves:
Tue Aug 22 15:56:24 2023 - [info] 172.16.1.52(172.16.1.52:3306) Version=5.7.28-log (oldest major version between slaves) log-bin:enabled
Tue Aug 22 15:56:24 2023 - [info] GTID ON
Tue Aug 22 15:56:24 2023 - [info] Replicating from 172.16.1.51(172.16.1.51:3306)
Tue Aug 22 15:56:24 2023 - [info] Starting GTID based failover.
Tue Aug 22 15:56:24 2023 - [info]
Tue Aug 22 15:56:24 2023 - [info] ** Phase 1: Configuration Check Phase completed.
Tue Aug 22 15:56:24 2023 - [info]
Tue Aug 22 15:56:24 2023 - [info] * Phase 2: Dead Master Shutdown Phase..
Tue Aug 22 15:56:24 2023 - [info]
Tue Aug 22 15:56:24 2023 - [info] Forcing shutdown so that applications never connect to the current master..
Tue Aug 22 15:56:24 2023 - [warning] master_ip_failover_script is not set. Skipping invalidating dead master IP address.
Tue Aug 22 15:56:24 2023 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master.
Tue Aug 22 15:56:25 2023 - [info] * Phase 2: Dead Master Shutdown Phase completed.
Tue Aug 22 15:56:25 2023 - [info]
Tue Aug 22 15:56:25 2023 - [info] * Phase 3: Master Recovery Phase..
Tue Aug 22 15:56:25 2023 - [info]
Tue Aug 22 15:56:25 2023 - [info] * Phase 3.1: Getting Latest Slaves Phase..
Tue Aug 22 15:56:25 2023 - [info]
Tue Aug 22 15:56:25 2023 - [info] The latest binary log file/position on all slaves is mysql-bin.000002:725
Tue Aug 22 15:56:25 2023 - [info] Retrieved Gtid Set: 06fdc979-3cb2-11ee-8345-000c29948844:1-2
Tue Aug 22 15:56:25 2023 - [info] Latest slaves (Slaves that received relay log files to the latest):
Tue Aug 22 15:56:25 2023 - [info] 172.16.1.52(172.16.1.52:3306) Version=5.7.28-log (oldest major version between slaves) log-bin:enabled
Tue Aug 22 15:56:25 2023 - [info] GTID ON
Tue Aug 22 15:56:25 2023 - [info] Replicating from 172.16.1.51(172.16.1.51:3306)
Tue Aug 22 15:56:25 2023 - [info] The oldest binary log file/position on all slaves is mysql-bin.000002:725
Tue Aug 22 15:56:25 2023 - [info] Retrieved Gtid Set: 06fdc979-3cb2-11ee-8345-000c29948844:1-2
Tue Aug 22 15:56:25 2023 - [info] Oldest slaves:
Tue Aug 22 15:56:25 2023 - [info] 172.16.1.52(172.16.1.52:3306) Version=5.7.28-log (oldest major version between slaves) log-bin:enabled
Tue Aug 22 15:56:25 2023 - [info] GTID ON
Tue Aug 22 15:56:25 2023 - [info] Replicating from 172.16.1.51(172.16.1.51:3306)
Tue Aug 22 15:56:25 2023 - [info]
Tue Aug 22 15:56:25 2023 - [info] * Phase 3.3: Determining New Master Phase..
Tue Aug 22 15:56:25 2023 - [info]
Tue Aug 22 15:56:25 2023 - [info] Searching new master from slaves..
Tue Aug 22 15:56:25 2023 - [info] Candidate masters from the configuration file:
Tue Aug 22 15:56:25 2023 - [info] Non-candidate masters:
Tue Aug 22 15:56:25 2023 - [info] New master is 172.16.1.52(172.16.1.52:3306)
Tue Aug 22 15:56:25 2023 - [info] Starting master failover..
Tue Aug 22 15:56:25 2023 - [info]
From:
172.16.1.51(172.16.1.51:3306) (current master)
+--172.16.1.52(172.16.1.52:3306)
To:
172.16.1.52(172.16.1.52:3306) (new master)
Tue Aug 22 15:56:25 2023 - [info]
Tue Aug 22 15:56:25 2023 - [info] * Phase 3.3: New Master Recovery Phase..
Tue Aug 22 15:56:25 2023 - [info]
Tue Aug 22 15:56:25 2023 - [info] Waiting all logs to be applied..
Tue Aug 22 15:56:25 2023 - [info] done.
Tue Aug 22 15:56:25 2023 - [info] Getting new master's binlog name and position..
Tue Aug 22 15:56:25 2023 - [info] mysql-bin.000001:725
Tue Aug 22 15:56:25 2023 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='172.16.1.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='xxx';
Tue Aug 22 15:56:25 2023 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: mysql-bin.000001, 725, 06fdc979-3cb2-11ee-8345-000c29948844:1-2
Tue Aug 22 15:56:25 2023 - [warning] master_ip_failover_script is not set. Skipping taking over new master IP address.
Tue Aug 22 15:56:25 2023 - [info] ** Finished master recovery successfully.
Tue Aug 22 15:56:25 2023 - [info] * Phase 3: Master Recovery Phase completed.
Tue Aug 22 15:56:25 2023 - [info]
Tue Aug 22 15:56:25 2023 - [info] * Phase 4: Slaves Recovery Phase..
Tue Aug 22 15:56:25 2023 - [info]
Tue Aug 22 15:56:25 2023 - [info]
Tue Aug 22 15:56:25 2023 - [info] * Phase 4.1: Starting Slaves in parallel..
Tue Aug 22 15:56:25 2023 - [info]
Tue Aug 22 15:56:25 2023 - [info] All new slave servers recovered successfully.
Tue Aug 22 15:56:25 2023 - [info]
Tue Aug 22 15:56:25 2023 - [info] * Phase 5: New master cleanup phase..
Tue Aug 22 15:56:25 2023 - [info]
Tue Aug 22 15:56:25 2023 - [info] Resetting slave info on the new master..
Tue Aug 22 15:56:25 2023 - [info] 172.16.1.52: Resetting slave info succeeded.
Tue Aug 22 15:56:25 2023 - [info] Master failover to 172.16.1.52(172.16.1.52:3306) completed successfully.
Tue Aug 22 15:56:25 2023 - [info] Deleted server1 entry from /etc/mha/app1.cnf .
Tue Aug 22 15:56:25 2023 - [info]
结果报告:
----- Failover Report -----
app1: MySQL Master failover 172.16.1.51(172.16.1.51:3306) to 172.16.1.52(172.16.1.52:3306) succeeded
Master 172.16.1.51(172.16.1.51:3306) is down!
Check MHA Manager logs at master-61:/var/log/mha/app1/manager.log for details.
Started automated(non-interactive) failover.
Selected 172.16.1.52(172.16.1.52:3306) as a new master.
172.16.1.52(172.16.1.52:3306): OK: Applying all logs succeeded.
172.16.1.52(172.16.1.52:3306): Resetting slave info succeeded.
Master failover to 172.16.1.52(172.16.1.52:3306) completed successfully.
在完成故障转移后,可以看到现在的master是db-52;同时,manager还修改了自己的配置文件,挂掉的原master被删除
[server default]
manager_log=/var/log/mha/app1/manager.log
manager_workdir=/var/log/mha/app1.log
master_binlog_dir=/mysql_binlog/
password=123456
ping_interval=5
repl_password=123456
repl_user=repl
ssh_user=root
user=mha
[server2]
hostname=172.16.1.52
port=3306
除此之外,通过masterha_check_status命令还可以知道,一旦mha完成主从切换,manager管理进程就会自动终止。
[root@master-61 ~]#masterha_check_status --conf=/etc/mha/app1.cnf
app1 is stopped(2:NOT_RUNNING).
MHA故障修复
方法比较简单
- 重启挂掉的mysql数据库
- 通过
CHANGE MASTER TO使其成为新的主库的从库。 - 修复MHA Manager的配置文件
db-51重新加入主从复制
systemctl start mysqld
change master to master_host='172.16.1.52', master_user='repl', master_password='123456' , MASTER_AUTO_POSITION=1;
start slave;
可以在db-52上进行确认:
mysql> show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 51 | | 3306 | 52 | 06fdc979-3cb2-11ee-8345-000c29948844 |
+-----------+------+------+-----------+--------------------------------------+
1 row in set (0.00 sec)
修复MHA Manager配置文件
[server default]
manager_log=/var/log/mha/app1/manager.log
manager_workdir=/var/log/mha/app1.log
master_binlog_dir=/mysql_binlog/
password=123456
ping_interval=5
repl_password=123456
repl_user=repl
ssh_user=root
user=mha
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
再次确认ssh链接和repl主从复制状态后,重新启动MHA就可以了。





