

On this page
Zookeeper简介
Zookeeper是一个开源的分布式协同服务系统,一般在服务器集群中用作配置中心或者注册中心,基于zookeeper的事件watcher系统,当服务器配置发生改变时可以第一时间通知所有订阅该节点的频道
配置中心
举个例子,假如我们有一个java应用需要实现基本的增删改查功能,那么我们就可以将数据库的ip,用户名和密码等信息存储在zookeeper的某个节点中,并且让java应用订阅这个节点;当配置发生变化时,java应用就能通过watcher监听器捕获到这个数据发生的变化,并重新来配置中心读取数据。
注册中心
注册中心有三种角色:
- 服务提供者(RPC Server):在启动时,向 Registry 注册自身服务,并向 Registry 定期发送心跳汇报存活状态。
- 服务消费者(RPC Client):在启动时,向 Registry 订阅服务,把 Registry 返回的服务节点列表缓存在本地内存中,并与 RPC Sever 建立连接。
- 服务注册中心(Registry):用于保存 RPC Server 的注册信息,当 RPC Server 节点发生变更时,Registry 会同步变更,RPC Client 感知后会刷新本地 内存中缓存的服务节点列表。
最后,RPC Client 从本地缓存的服务节点列表中,基于负载均衡算法选择一台 RPC Sever 发起调用。
举个例子,mysql主从复制中有master和slave的角色之分,master负责写操作,slave负责读操作,那么如何让其他的应用知道谁是master,谁是slave呢?这就是注册中心的作用了。
Zookeeper充当一个服务注册表(Service Registry),让多个服务提供者形成一个集群,让服务消费者通过服务注册表获取具体的服务访问地址(Ip+端口)去访问具体的服务提供者。
如下图所示:
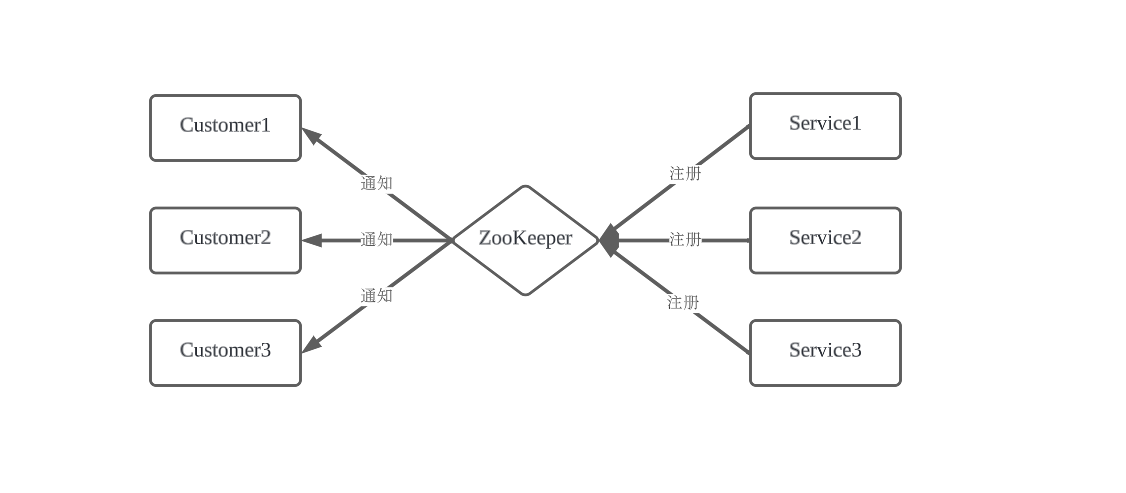
每当一个服务提供者部署后都要将自己的服务注册到zookeeper的某一路径上,如: /{service}/{version}/{ip:port}, 比如我们有两个服务profile和cart代表了用户个人信息功能和购物称功能,他们被分别部署到两台机器上,那么Zookeeper上就会创建两条目录:分别为/profile/1.0.0/100.19.20.01:16888 和 /cart/1.0.0/100.19.20.02:16888。
ZooKeeper是一个树状的存储结构,下面这张图更直观的表现了注册中心大概得样子:
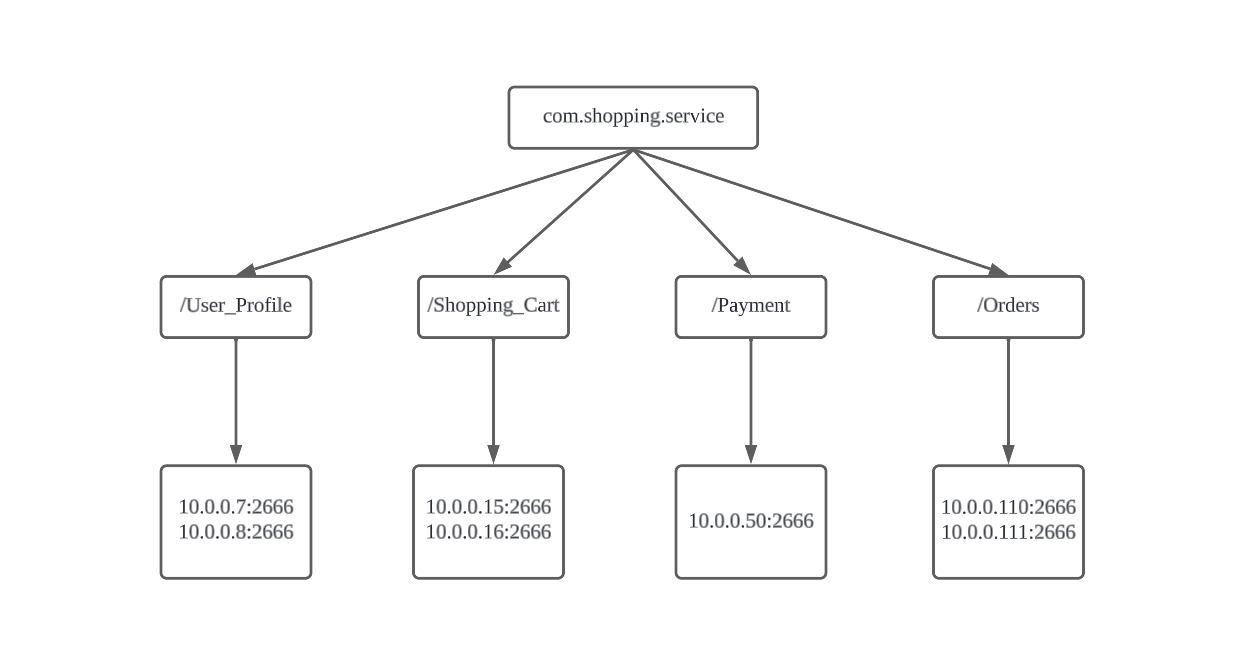
在Zookeeper中,进行服务注册,实际上就是在Zookeeper中创建了一个Znode节点,该节点存储了该服务的IP、端口、调用方式(协议、序列化方式)等.
该节点承担着最重要的职责,它由服务提供者(发布服务时)创建,以供服务消费者获取节点中的信息,从而定位到服务提供者真正IP,发起调用。
安装zookeeper
安装JDK
可以看这篇文章

安装zookeeper
下载zookeeper压缩包
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.6/apache-zookeeper-3.5.6-bin.tar.gz
解压缩
tar -xf apache-zookeeper-3.5.6-bin.tar.gz
创建软连接
ln -s /opt/apache-zookeeper-3.5.6-bin /opt/zookeeper
创建zookeeper数据目录
mkdir /opt/zookeeper/data
创建并修改zookeeper配置文件
在 conf/ 目录下提供了模板配置文件 zoosample.cfg ,将其复制为 zoo.cfg 即可。
cp zoo_sample.cfg zoo.zfg
修改目录路径
dataDir=/opt/zookeeper/data
启动zookeeper
[root@zk-90 /opt/zookeeper/conf]#/opt/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
部署zookeeper集群
在安装单机zookeeper的基础上,还要执行以下步骤
为三个zookeeper实例创建服务器编号
要求存储编号的文件名为myid,且存放在数据目录中:
echo '1' > /opt/zookeeper/data/myid
echo '2' > /opt/zookeeper/data/myid
echo '3' > /opt/zookeeper/data/myid
启动zookeeper
/opt/zookeeper/bin/zkServer.sh start
启动后应该可以发现系统在数据目录下自动生成了几个文件
修改配置文件,添加集群信息
为每个zookeeper实例的配置文件添加如下内容
server.1=10.0.0.90:2888:3888
server.2=10.0.0.91:2888:3888
server.3=10.0.0.92:2888:3888
格式:server.节点ID=ip:数据同步端口:选举端口
选举端口:主节点挂了,选举新的主节点的通信端口。
使用ansible-playbook一键部署zookeeper集群
ansible hosts配置:
[zoo]
10.0.0.90 myid=1
10.0.0.91 myid=2
10.0.0.92 myid=3
ansible-playbook:
---
- name: deploy zookeeper cluster
hosts: zoo
tasks:
- name: 01 - copy jdk package
copy:
src: /opt/jdk-8u221-linux-x64.tar.gz
dest: /opt/
- name: 02 - unarchive jdk package
unarchive:
src: /opt/jdk-8u221-linux-x64.tar.gz
dest: /opt/
remote_src: true
- name: 03 - create soft link for jdk
file:
state: link
src: /opt/jdk1.8.0_221/
dest: /opt/jdk8
- name: 04 - configure PATH
lineinfile:
dest: /etc/profile
line: "{{ item }}"
loop:
- export JAVA_HOME=/opt/jdk8
- export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
- export CLASSPATH=.$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tools.jar
- name: 05 - download zookeeper
get_url:
url: https://archive.apache.org/dist/zookeeper/zookeeper-3.5.6/apache-zookeeper-3.5.6-bin.tar.gz
dest: /opt/
- name: 06 - unarchive zookeeper package
unarchive:
src: /opt/apache-zookeeper-3.5.6-bin.tar.gz
dest: /opt/
remote_src: true
- name: 07 - create soft link for zookeeper
file:
state: link
src: /opt/apache-zookeeper-3.5.6-bin/
dest: /opt/zookeeper
- name: 08 - create zookeeper data directory
file:
state: directory
path: /opt/zookeeper/data
- name: 09 - create zookeeper config file
shell:
cmd: cp /opt/zookeeper/conf/zoo_sample.cfg /opt/zookeeper/conf/zoo.cfg
- name: 10 - modify zookeeper config file
shell:
cmd: sed -i '/^dataDir/c dataDir=/opt/zookeeper/data' /opt/zookeeper/conf/zoo.cfg
- name: 11 - create serverid file
file:
state: touch
path: /opt/zookeeper/data/myid
- name: 12 - set server id
shell:
cmd: echo {{ myid }} > /opt/zookeeper/data/myid
- name: 13 - add cluster info
lineinfile:
dest: /opt/zookeeper/conf/zoo.cfg
line: "{{ item }}"
loop:
- server.1=10.0.0.90:2888:3888
- server.2=10.0.0.91:2888:3888
- server.3=10.0.0.92:2888:3888
zookeeper集群中的角色
zookeeper集群中有三种角色,分别是:
Leader(领导者)
相当于主库,在集群中只能有一个Leader,其主要作用是:
- 发起与提交写请求:
所有的跟随者Follower与观察者Observer节点的写请求都会转交给领导者Leader执行。Leader接受到一个写请求后,首先会发送给所有的Follower,统计Follower写入成功的数量。当有超过半数的Follower写入成功后,Leader就会认为这个写请求提交成功,通知所有的Follower commit这个写操作,保证事后哪怕是集群崩溃恢复或者重启,这个写操作也不会丢失。 - 与learner保持心跳
- 崩溃恢复时负责恢复数据以及同步数据到Learner
Follower(追随者)
Follower在集群中可以有多个,其主要作用是:
- 与Leader保持心跳连接
- 当Leader挂了的时候,经过投票后成为新的leader。leader的重新选举是由Follower们内部投票决定的。
- 向leader发送消息与请求
- 处理leader发来的消息与请求
#Observer(观察者)
Observer是zookeeper集群中最边缘的存在。Observer的主要作用是提高zookeeper集群的读性能。通过leader的介绍我们可以zookeeper的一个写操作是要经过半数以上的Follower确认才能够写成功的。那么当zookeeper集群中的节点越多时,zookeeper的写性能就 越差。为了在提高zookeeper读性能(也就是支持更多的客户端连接)的同时又不影响zookeeper的写性能,zookeeper集群多了一个儿子Observer,只负责:
- 与leader同步数据
- 不参与leader选举,没有投票权。也不参与写操作的提议过程。
- 数据没有事务化到硬盘。即Observer只会把数据加载到内存。
zookeeper选举机制
- zookeeper的选举机制要求任何一台主机至少获得三票才能成为leader,也因为如此,zookeeper集群的最小主机数量是3。
- zookeeper的选举票数是基于myid的,myid的数值越大获得的票数越多,因此在初始化选举时,最好给目标Leader设定一个最大的myid。
zookeeper客户端连接服务端
使用提供的客户端脚本 zkCli.sh
./zkCli.sh -server 10.0.0.92
znode管理命令
- stat查看结点状态
- ls查看一个节点下的子节点
- -s 查看节点状态,等同于stat
- -R 递归查询某个节点下的所有子节点
- create 创建结点
- -e 创建临时结点(退出客户端链接后节点消失)
- -s 创建有序节点:节点的key后面会自动加上序号
- -t 创建有存活时间限制的节点
- get 获得节点的值
- -s 等同与stat
- set 给节点设置一个值
- delete 删除节点(前提是被删除的结点没有子节点)
- deleteall 递归删除节点
节点事件watcher
- watcher是一次性的,触发后就会消失
- 通过stat -w给节点加上watcher
- 父结点watcher事件
- 创建父结点,触发NodeCreated
- 创建父节点数据,触发NodeDataChanged
- 删除父节点,触发,NodeDeleted
- 子节点事件
- 父节点设置watcher,创建子节点,触发NodeChildrenChanged
- 父节点设置watcher,删除子节点,触发NodeChildrenChanged
- 父节点设置watcher,修改子节点,无事件
zookeeper权限控制
主要是基于 setAcl 命令。
有以下几种权限:
- c: create - 允许创建子节点
- w:write - 允许设置节点的value
- r:read - 允许获取子节点、获取节点value
- d:delete - 可以删除子节点
- a:admin - 管理员权限
权限可以像chmod命令一样组合使用。
world权限类型
world:anyone权限类型是允许任何用户对节点执行符合权限限制的操作(crwda)。
语法:
# setAcl /node world:anyone:权限位
# 例如:
setAcl /acl-node world:anyone:rw
设置后所有用户对该节点只能执行read和write操作。
对delete权限的实验
创建一个三级结点
create /acl-node2/test1/t1
# 设置权限
setAcl /alc-node2 world:anyone:rw
尝试删除父结点
[zk: 10.0.0.92(CONNECTED) 63] deleteall /alc-node2
Authentication is not valid : /alc-node2/test1
失败了,因为我们没有删除这个节点的权限;
尝试删除该节点的子节点
[zk: 10.0.0.92(CONNECTED) 66] delete /alc-node2/test1
Authentication is not valid : /alc-node2/test1
# 看似失败了,其实没有
[zk: 10.0.0.92(CONNECTED) 68] ls -R /alc-node2
/alc-node2
/alc-node2/test1
可以发现我们没能删除test1这个二级结点,但是t1这个三级结点却消失了,这是因为二级结点test1受父结点的权限限制无法被删除,但是二级结点本身却是默认权限,即:
[zk: 10.0.0.92(CONNECTED) 69] getAcl /alc-node2/test1
'world,'anyone
: cdrwa
因此三级不受父结点的权限影响,是可以被删除的。
所以可以得出结论: 每一个节点的权限限制最多影响到自己下一级的子节点,而不会影响下下级的子节点。
Auth权限类型
Auth就是为节点指定那个用户才能执行操作。
语法: setAcl /node auth:username:password:权限位
实践
创建一个用于实验的节点
[zk: 10.0.0.92(CONNECTED) 70] create /auth-node 123456
Created /auth-node
[zk: 10.0.0.92(CONNECTED) 71] get /auth-node
123456
注册用户
addauth digest mike:123456
设置Auth权限
#为这个用户设置的auth-node节点的rwcd权限
setAcl /auth-node auth:mike:123456:rwcd
需要重新启动客户端才能生效设置
尝试获得这个节点的value
[zk: 10.0.0.92(CONNECTED) 1] get /auth-node
org.apache.zookeeper.KeeperException$NoAuthException: KeeperErrorCode = NoAuth for /auth-node
被拒绝了,因为没有进行权限验证,验证的方式和注册用户是一样的方法,都是通过 addauth 命令。
[zk: 10.0.0.92(CONNECTED) 2] addauth digest mike:123456
[zk: 10.0.0.92(CONNECTED) 3] get /auth-node
123456
ip权限类型
很明显,这个方法就是限定只允许特定ip对节点进行操作。
语法: setAcl /node ip:ipaddress:权限位
实践
创建节点并设置ip
[zk: 10.0.0.92(CONNECTED) 4] create /ip-node
Created /ip-node
# 只允许ip为10.0.0.90的客户端操作这个节点
[zk: 10.0.0.92(CONNECTED) 5] setAcl /ip-node ip:10.0.0.90:rwcd
使用另一台机器进行操作
[zk: localhost:2181(CONNECTED) 3] get /ip-node
org.apache.zookeeper.KeeperException$NoAuthException: KeeperErrorCode = NoAuth for /ip-node
无权限





